
Evolutionen af kunstig intelligens og væksten af kontekstvinduet
I de seneste årtier har udviklingen af kunstig intelligens (AI) skredet frem med bemærkelsesværdig hastighed. Fra de tidlige dage med simple, regelbaserede systemer til nutidens avancerede sprogteknologi i form af store sprogmodeller (LLM) har AI undergået en imponerende udvikling, som har potentialet til at revolutionere, hvordan vi interagerer med teknologi og løser komplekse problemer.
Betydelige fremskridt er gjort inden for udvidelsen af modellernes “kontekstvindue”. Kontekstvinduet refererer til den mængde tekst, en AI-model kan analysere på én gang for at forstå og generere sprog; det kan også ses som modellens umiddelbare hukommelse eller det aktuelle samtalevindue. Jo større vinduet er, desto bedre er modellens evne til at forstå konteksten og producere sammenhængende, meningsfuld tekst.
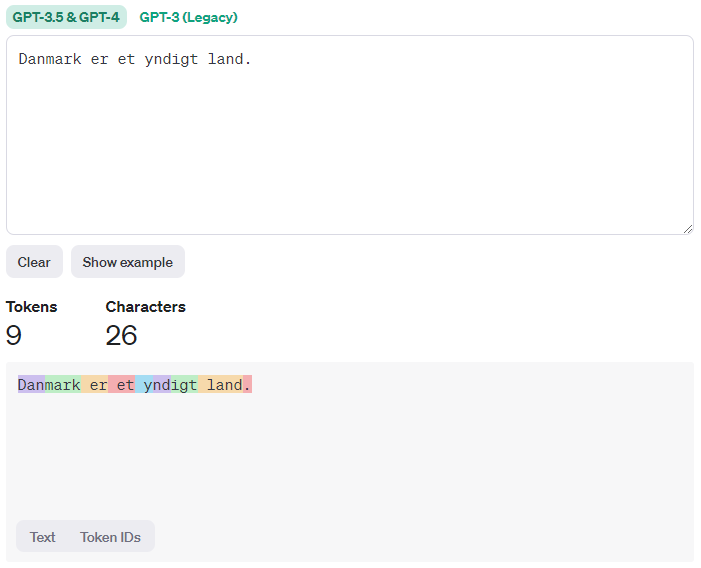
Sprogmodeller læser ikke ord som mennesker, men bruger i stedet “tokens”, som er en opdeling af ord i enheder, der minder om stavelser. For eksempel kan ordet “Danmark” opdeles i “Dan” og “mark”. Som tommelfingerregel svarer 100 tokens til cirka 40-50 ord.
I det vi anser som sprogteknologiens barndom var modellernes kontekst begrænset til kun et par hundrede tokens. Men takket være fremskridt inden for maskinlæring og forbedrede datasæt er kontekstvinduets størrelse vokset eksponentielt, hvilket har muliggjort mere avanceret sprogforståelse og tekstgenerering.
OpenAI har været en førende kraft bag denne udvikling og deres GPT-serie (Generative Pre-trained Transformer) har set en markant stigning i kontekstvinduets størrelse med hver iteration. Fra Google’s BERT og OpenAI’s GPT-1 med et beskedent kontekstvindue på 512 tokens, til de seneste modeller som GPT-4-1106 med et enormt vindue på 128.000 tokens, har OpenAI ført an i denne eksplosive vækst.
Ikke kun OpenAI, men også tech-giganter som Google, Anthropic og Meta har bidraget til denne udvikling. For eksempel har Googles nye model, Gemini-1.5-MW, en imponerende kapacitet på 10.000.000 tokens, hvilket understreger den imponerende skala, modellernes kontekstlængde har nået på kort tid.
Denne vækst har åbnet op for en lang række anvendelser inden for sprogforståelse, maskinoversættelse og tekstgenerering. Fra forbedring af AI-chatbots til at kunne føre chat samtaler med over tusindvis af sider, har den øgede modelstørrelse været afgørende for AI’s evne til at tackle komplekse opgaver.
Til trods for denne bemærkelsesværdige vækst står vi stadig over for udfordringer. Større kontekstvinduer kræver mere beregningskraft, yderligere data og avancerede algoritmer for at håndtere kompleksiteten. Desuden rejser det spørgsmål om skalering og bæredygtighed, da de store modeller typisk kræver adgang til massive GPU-ressourcer, som kun findes i store datacentre.
Med denne hurtige udvikling forventes modellernes umiddelbare hukommelse at spille en central rolle i fremtidens AI. Med fortsatte fremskridt inden for datalogi, maskinlæring og modeltræning er det sandsynligt, at vi kun har set begyndelsen på, hvad disse modeller er i stand til, og de muligheder, de åbner for fremtiden.
Ligesom udviklingen af RAM i vores computere er eksploderet med den teknologiske udvikling, kan man trække en analogi mellem sprogmodellernes kontekstvindue og computerens RAM. Med Googles Gemini’s nye kontekstvindue på 10.000.000 tokens markeres en væsentlig milepæl for udviklingen af sprogteknologi.
Den eksponentielle vækst inden for AI og teknologi gør det spændende at se, hvad fremtiden bringer, måske snart en ny generation af GPT-modeller, nu hvor GPT-4 nærmere sig sin 1. fødselsdag fra sin udgivelse i marts 2023.
Skriv et svar